Revamp your document workflows with OCR

Contents
What is OCR?
OCR is the mechanical or electronic conversion of images, typically scanned documents, into selectable, searchable, and editable text. Good OCR software will allow you to work in multiple languages and scripts without negatively affecting its character recognition accuracy rate.
Some typical benefits of OCR include:
- Ability to search through your documents
- Faster and increased accuracy of data
- Reduced paper costs through digitalization
- Legal compliance with certain industry regulations
How can OCR revamp my workflow?
OCR can have a major positive impact on your document management workflows, regardless of your industry. Some of the most immediate impacts include the streamlining of workflows by directly converting scanned images to PDF documents. This enables you to instantly search through content, reduce errors in these PDF documents by correcting any errors quickly and effectively.
Almost all companies have large amounts of “badly” formatted PDFs, meaning PDFs that are image based. These are usually scanned. If you want these PDFs to be searchable, they must undergo OCR.
The level of automation OCR provides to your company can enable you to eliminate human error by letting PDF OCR software do the work. This means your staff can focus on more important tasks that a machine can’t do better (yet!). The most efficient way you can automate conversion is with PDF software that has built-in OCR functionality.
Read on as we take a look at 5 industries and provide use cases for OCR. Many of these use cases will apply to any industry so even if your specific field is not listed, you will still recognize the relevant benefits.
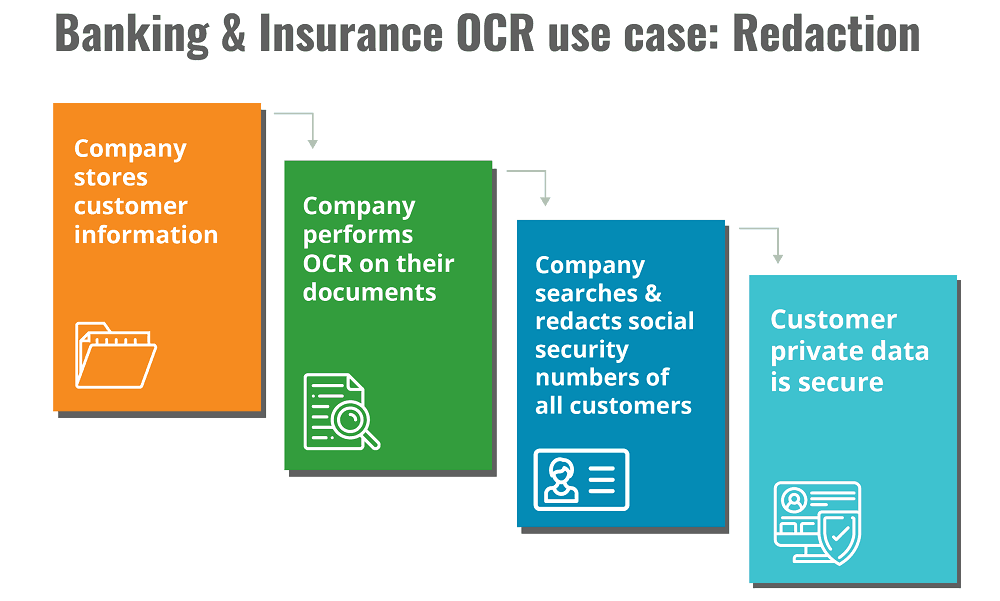
Banking & Insurance OCR use case: Redaction
Redaction is critical for businesses that operate in industries where data security is stringently regulated. It ensures that confidential material is not viewed by the wrong people.
Banking and insurance institutions consistently require redaction of customer information in their workflows. Even with the relatively recent introduction of GDPR in the EU, documents that contain Personally Identifiable Information (PII) are subject to GDPR.
OCR technology enables you to automate your redaction with batch processing. Once you come up with a criterion, you can perform the OCR and get the documents returned fully redacted where applicable, eg. with your customers’ SSNs fully removed from any documents. This ensures that your documents are compliant and secure. It also massively reduces the manual workload of your team and ensures they only need to deal with exceptions/errors, and can focus on adding value in more important areas.
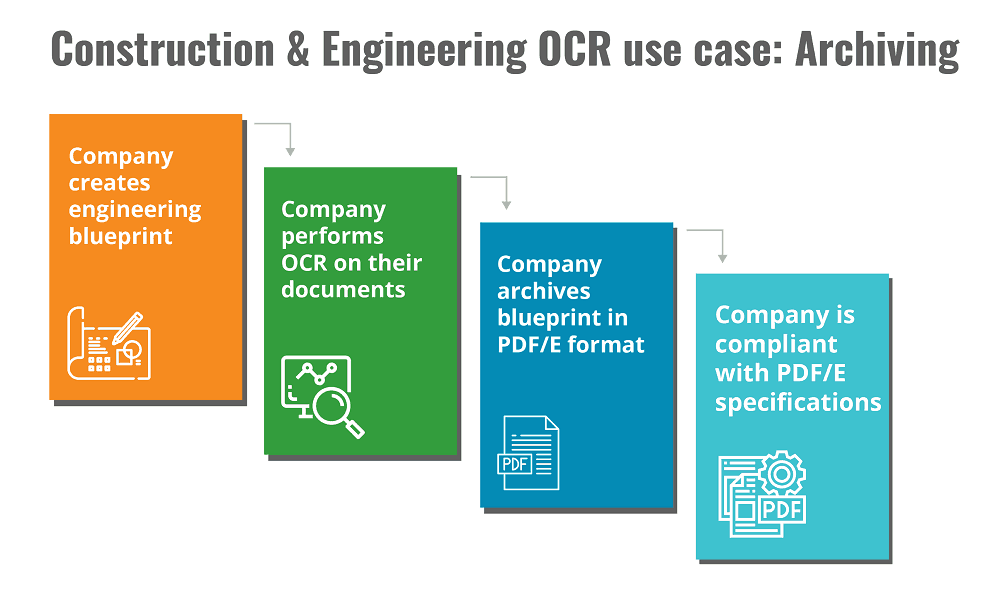
Construction & Engineering OCR use case: Archiving
OCR works great for engineering companies who use documents such as blueprints. Archiving in PDF/E, a PDF ISO standard for engineering drawings, is easily performed with top of the line OCR technology and ensures that you are compliant with the standard.
Zonal OCR is particularly useful when it comes to engineering workflows. Zonal OCR goes beyond converting your scanned images into text. It understands the structure of a document through defined zones. This enables you to distinguish data fields from one another and archive the appropriate data as needed.
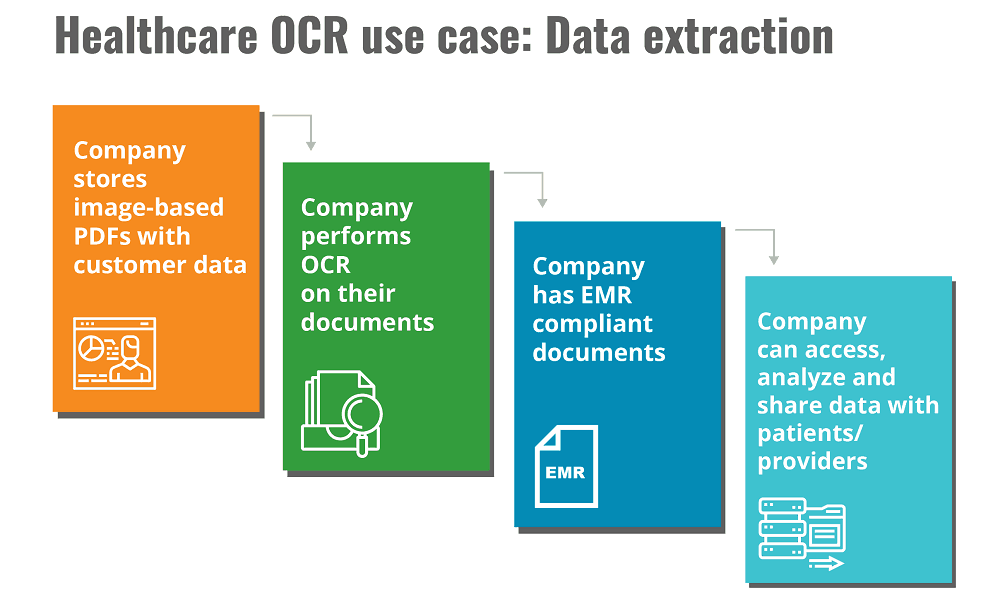
Healthcare OCR use case: Data extraction
For operators in the healthcare industry, OCR can help you capture discrete data from poorly formatted documents and transform it into an EMR-compliant document. How does this benefit hospitals and other healthcare companies? It makes it much easier for healthcare providers to access, analyze and share with both patients and other providers in the industry, all which result in better healthcare for the end patients thanks to these workflow improvements.
Ensuring your healthcare company has up-to-date clinical data obtained via performing OCR also enables the EMR to flag important patient safety concerns based on the data captured from scanned documents.
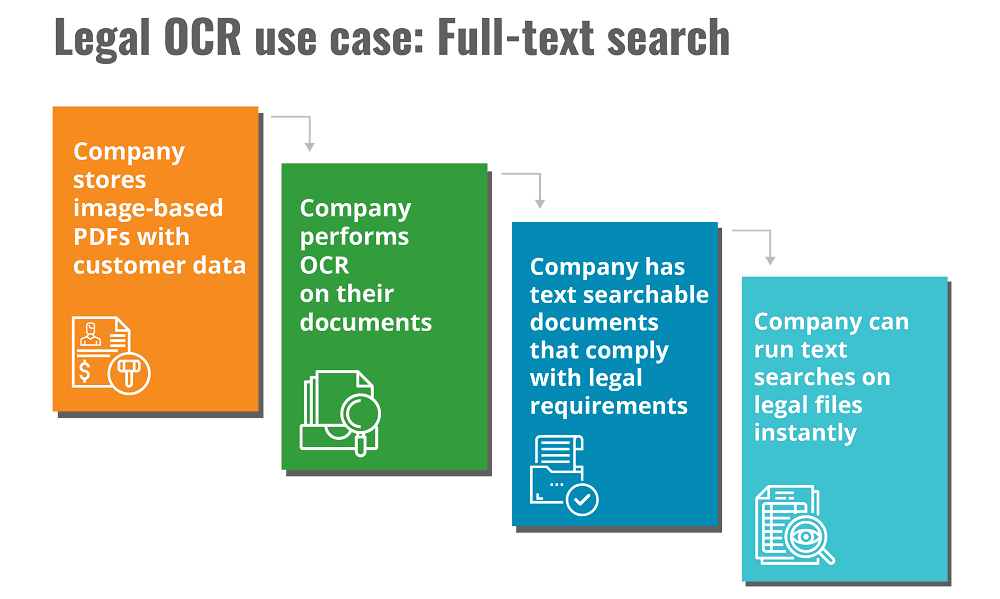
Legal OCR use case: Full-text search
Maintaining control over a never-ending pile of documents is a constant battle for legal companies. Consider the amount of time spent scanning physical copies of legal documents that are then stored but the content inside cannot be filtered with a simple text-search. Locating text within multi-page image files is an inefficient task. This is because OCR has not been performed.
Full-text search is defined as “searching a single computer-stored document or a collection in a full-text database”. It’s important to note that many jurisdictions across the globe now require any e-filed documents to be text searchable. This means that not only workflow efficiency is key, but compliance with the law too.
For a legal company that maintains a high amount of paper documents, OCR can transform large amounts of image-based PDFs that also have the benefit of being smaller in size to store and access. Good OCR software will also run quickly, another important consideration for those with a large scanned document backlog.
When it comes to OCR, Foxit PDF SDK leads the market. Our OCR add-on is able to accurately recognize more characters than the competition. To find out more about how you can revamp your workflows with OCR get in touch with us below.
